Time To Rethink on your Database

Even though it may be the wrong tool for the job, the years of development behind the relational database ensure its popularity — for the moment
– Max Schireson, MongoDB
We see many applications in the web as so elegant, beautiful and fast. What make them as such is the part that we can’t see. At the core of most large-scale services and applications includes a high-performance database management solution. Here is where the data lives. Better applications require the capability to store and retrieve data with high accuracy, speed, and reliability. Several data storage solutions are available to manipulate the data your applications need.
The main 3 categories of such database management solutions are,
- Direct file system storage in files,
- Relational Database (RD) Management Solutions and
- NoSQL Databases.
We’ve been using databases such as MySQL, PostgreSQL etc., which are known as SQL Databases or Relational Database. They are being used by many companies today. But the NoSQL database concept is a little different from what you already knew with RDBMS. They’re wonderful!
This tiny article is going to concentrate on some bare bone basics of MongoDB, the famous NoSQL database, and some important MongoDB database design principles that you should be aware of.
NoSQL DBS. What that mean?
NoSQL stands for “No-SQL” or “non-relational” or “not only sql”. So in NoSQL databases, we are less likely to use traditional SQL queries. NoSQL databases provides a mechanism for storage and retrieval of data which is modeled in means other than the tabular relations used in Relational Database (RDBMS).
RDBMS store data in a well-structured tabular form, which is not always good. Especially when we need to handle immense amount of data of different categories. The “one size fits all” approach of SQL will fall in question. This has led to the emergence of NoSQL DBMS. With NoSQL, unstructured data can be stored and it does not require fixed table schemas. The structured approach of RDBMS database like SQL slows down performance as data volume or size gets bigger and it is also not scalable to meet the needs of high end applications.
So NoSQL can be perceived as a completely different framework of databases that allows high-performance, rapid processing of information at a much bigger scale. This is the database well-adapted to the high demands of Big Data and Internet of Things. We don’t need to know in advance exactly what kind of data we’ll be collecting and storing. You can collect a lot more data of different kinds and can access and analyze them much faster.
The MongoDB
MongoDB is an open source, document-oriented, highly scalable database solution. MongoDB stores data using a flexible document data model that is similar to JSON. Fields can vary from document to document. This flexibility allows development teams to evolve the data model rapidly as their application requirements change. Today, MongoDB is used by the giants like Expedia, MetLife, and Bosch etc.
MongoDB enables us to deal with:
- Large volumes of rapidly changing structured, semi-structured, and unstructured data
- Schema less data
- Better data consistency
- Object-oriented programming that is easy to use and flexible
- Geographically distributed scale-out architecture instead of expensive, monolithic architecture.
We can compare the relationship of RDBMS with MongoDB as follows:
| RDBMS | MongoDB |
| Database | Database |
| Table | Collection |
| Tuple/Row | Document |
| Column | Field |
| Table Join | Embedded / Referenced Documents |
| Primary Key | MongoDB provides a default _id key |
Table 1: Comparison of RDBMS with MongoDB
Below is a sample MongoDB document. As said, MongoDB stores documents in JSON like structures.
{ _id: ObjectId(7ddf78ad8902c), title: 'This is a sample document', description: 'MongoDB is a no sql database', url: 'http://www.mongodb.org', likes: 100 }
Dynamic Schema
RDBMS require schemas be defined before you can actually add data to the database. (Remember the times when you defined tables in MySQL). For an instance, we might want to store data about our friends such as phone numbers, first and last name and address – an SQL database needs to know what you are storing in advance.
This approach fits badly with dynamic development, because each time you complete new features, the schema of your database often needs to change. So if you decide, a few iterations into development, that you’d like to store your friends’ favorite food in addition to their addresses and phone numbers, you’ll need to add that column to the database, and then migrate the entire database to the new schema. Wired, seriously!
NoSQL databases are built to allow the insertion of data without a predefined schema. That makes it easy to make significant application changes in real-time, without worrying about service interruptions – which means development is faster, code integration is more reliable, and less database administrating time is needed. Yeah, finally you can go ahead and say bye-bye to notorious migration scripts.
Basic Principles of Data Modeling
Data in MongoDB has a flexible schema. Unlike SQL databases, where you must determine and declare a table’s schema before inserting data, MongoDB’s collections do not enforce document structure. Here we are free to store data in random structure, which’s cool. But in practice, however, the documents in a collection share a similar structure.
The key challenge in the application development is data modeling. When you design your data models, hold performance in mind. You should balance the needs of application and performance characteristics of database engine during the design as well as coding.
“Show me your code and conceal your data-structures, and I shall continue to be mystified. Show me your data-structures, and I won’t usually need your codes; they’ll be obvious. ”
– Fred Brooks, “The Mythical Man Month”
Modeling the Document
Here is where you have to probably pause all your activities and be concentrated. Keep in mind that you are designing the foundation of your scalable application!
The key decision in designing data models for MongoDB applications revolves around the structure of documents and how the application represents relationships between data. There are 2 methods through which you can represent the relationships:
- References and
- Embedded documents.
Choosing the right method for the right data has the point. If you slip here, you are more likely to be slipped everywhere! So be there with your mind.
References
These are Normalized Data models. References store the relationships between data by including links or references from one document to another.
In general, use normalized data models:
- When embedding would result in duplication of data but would not provide sufficient read performance advantages to outweigh the implications of the duplication.
- To represent more complex many-to-many relationships.
- To model large hierarchical data sets.
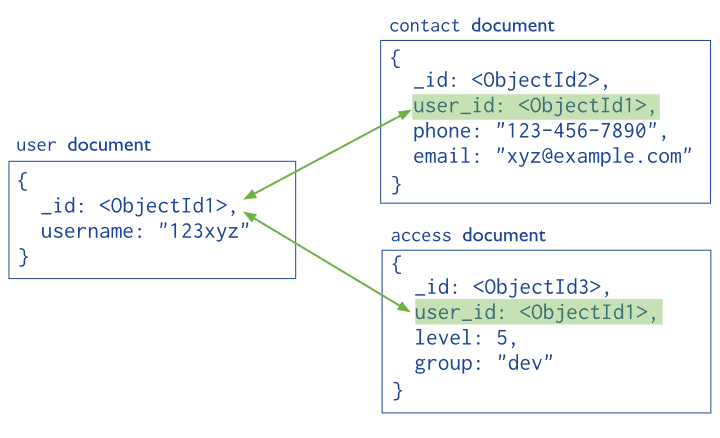
References provides more flexibility than embedding. However, client-side applications must issue follow-up queries to resolve the references. In other words, normalized data models may require more round trips to the server, which isn’t that nice.
Embedded Documents
Embedded documents represent relationships between data by storing related data in a single document structure. MongoDB documents make it possible to embed document structures in a field or array within a document. That means, fields within fields. These schema are generally known as “denormalized” models, and take advantage of MongoDB’s rich documents. These denormalized data models allow applications to retrieve and manipulate related data in a single database operation. Consider the diagram.

Embedded data models allow applications to store related pieces of information in the same database record. As a result, applications may need to issue fewer queries and updates to complete common operations.
If a single query could get all the requested documents without any follow-up queries, that would be awesome. In general, embedding provides better performance for read operations, as well as the ability to request and retrieve related data in a single database operation.
The Normal Forms and Why We Don’t Need Them Sometimes?
All of this are nice. But always keep in mind that storage is cheaper than processing time. While we use Reference model, the client-side applications has to issue follow-up queries to resolve the references, which consumes more processing. So normal forms won’t work well with all kinds of data sets. Fixing the best data sets for Reference and Embedded models is the key decision for your scalable application database to be awesome.
Duplication is good!
Deal with it! Duplication is sometimes good for performance. Take this example: My application needs to find ingredients of user’s favorite food. Assume that this application is used by millions of people and therefore the database is getting lots of hits. So we have to deliver the requested data in lightning speed. Storing the user data in one collection and food ingredients another collection reduces the performance. What we would get from the collection of user data is a reference to another collection of food ingredients. So the application has to fire extra queries to resolve the references, which consumes more processing time.
Now, if we duplicate the document containing ingredients of favorite food of a specific user and store that document inside the collection of user data (known as embedding), a single query fetches everything! No follow-up queries, no extra processing overheads. Thus KISS (Keeps It Simple Stupid)!
But when you adopt this model, consider update operations – consider the tradeoffs.
SQL vs MongoDB
This is an essential comparison worth checking. When you are in a position to choose between database systems, show some mercy to your life, read it.
Anything Else ?
Google Cloud Datastore is my next favorite.
Consider Cloud Datastore also if you are making an application at planet scale.
Let me know what’s on your mind! @vajahath7
Other Blogs:



Get in touch
Kickstart your project
with a free discovery session
Describe your idea, we explore, advise, and provide a detailed plan.












