Building BIG DATA Applications with Laravel and Mongodb

It’s a fact that the amount of data produced is insanely humongous and it keeps doubling every two years. Rumour has it that by the time we reach 2020, the data size will hit 44 trillion gigabytes! This is how term Big Data came into place which is now a buzzword all across the world, garnering popularity in the recent past.
Big data has already become a part and pack of robust business applications. Big Data helps businesses assimilate information in chunks and make use of the insights it provides. With a large volume of information always available on the internet and social media, businesses are trying to make use of the existing data for analysing various commercial, educational and technical possibilities. Big data technology has made it possible to analyse different kinds of information such as text, images, graphics, audio, video, geographical position and more resulting in useful information.
Several Big Data platforms has been developed to manage and organize the huge explosion of data. Almost 150 no-SQL solutions are available as of now of which MongoDB is considered to be the best Big Data Solution. This is because when it comes to unstructured data, Mongo DB truly stands out among all other databases. When you consider PHP framework, Laravel never fails to prove its worth. It simplifies repetitive tasks in huge Big Data development process. Needless to say, selecting the right technology and database is important when you handle and develop big data applications. In this blog we will analyse Mongo DB and Laravel on building big data applications.
Handling Big Data with Mongo DB
Big data poses quite a few challenges to the existing technologies. Unstructured data is one of them. Even though there are big players in the database that handle structured data in forms of tables and records efficiently, when it comes to unstructured data, it is considered as a big challenge. Very few databases such as NoSQL and MongoDB provide robust solutions in handling unstructured data. MongoDB is considered as a leader in handling unstructured data because it provides a flexible schema. MongoDB can analyse any type of data be it real-time or batch, it can save a lot of time and is cost effective. It is, by far, the best way to manage Big Data professionally.
CAP THEOREM
The CAP theorem which is also known as Bower’s theorem developed by Eric Brewer in 1999 states that distributed computing cannot achieve simultaneous Consistency, Availability, and Partition Tolerance while processing data. This theory is used to analyse several Big Data platforms.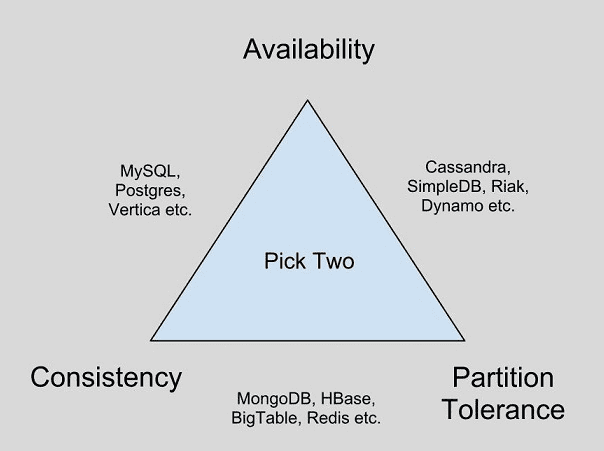
According to CAP theorem, Mongo DB provides consistency by default and also excels in partition tolerance although it is not the best in terms of data availability. When it comes to partition, MongoDB choose Consistency over availability. Let’s have a look on how MongoDB does replica sets.
As already known, a replica set has a single Primary node. The best way to commit data here is to write to that node and eventually wait for that particular data to commit to a majority of nodes in the set.
So when in partition the following happens:
* The primary node goes down and the systems become unavailable.
* The primary node gets disconnected from large number of secondary nodes
Bottom line is, MongoDB will always select consistency over availability whenever there is a crisis situation.
Laravel for Big Data
Laravel is an open source MVC PHP framework for developing Web Applications. One of the most significant features of Laravel is that it was developed to overcome the inefficient authorization and security features of CodeIgniter. When working with large chunks of data, as with Big Data, Laravel lets you access it in bulk and process it bit by bit. Laravel supports great scalability which lets programmers develop simple web applications to enterprise level applications. Laravel supports Eloquent, which is one of PHP’s robust frameworks for data handling, gives you faster access to the data. Laravel contains lighter templates and widgets such as JS and CSS code that are actively being used to manage Big Data. The widgets and plug-ins supported by Laravel make it much easier and more efficient to manage different types of data.
Combining Laravel and MongoDB
Geospatial indexing and client-side data delivery makes MongoDB a better choice for Big Data than Hadoop. PHP’s mastery in modelling data relations is also well-accepted. It is far easier to manage than Java. Even though Laravel does not directly support MongoDB, the Jenssegers API lets you connect to Laravel’s Eloquent. This is considered as the best way to make the most of MongoDB and Laravel that works great with Big Data individually. When used in combination, they result in the best real-time analytical applications that involve various batches of large chunks of information and long-running ETL. Since Laravel is already proven to be the best for Web Application development, MongoDB in handling unstructured Big Data, combining the power of Laravel and MongoDB results in delivering the best-performing Web Applications that deals with Big Data.
Our expert Laravel team has developed a query builder which support’s Cassandra(noSQL db), using the original Laravel API. We named it LACASSA. Integrated with AWS, it is a perfect solution for developers looking to use Laravel & Cassandra.
Cubet Techno Labs is one of the pioneers who understood the benefits of Laravel and adopted it as a core technology stack. We are one of noted Laravel application development company having experience working with some of the largest Laravel based applications.
Know More About This Topic from our Techies
Other Blogs:



Get in touch
Kickstart your project
with a free discovery session
Describe your idea, we explore, advise, and provide a detailed plan.












